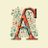
Tweet Overview
View this X/Twitter post from @aigclink published on 28 Kasım 2025 02:57. This post contains 1 images.
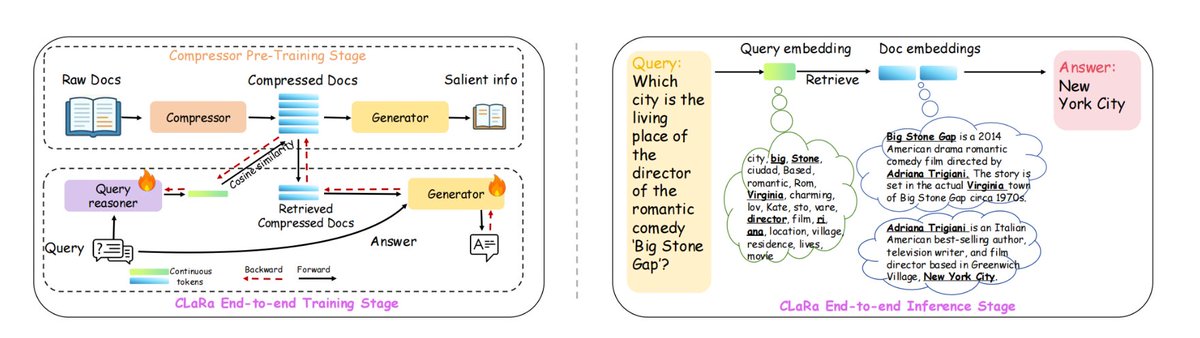
苹果新搞了一个RAG框架:ml-clara,解决长上下文处理效率低下、检索与生成优化过程的分离问题 其核心思想是,不要把整段文本塞给大模型,而是把“检索”和“生成”全部压缩到同一个可微的连续向量空间里,统一训练、一次推理 以此解决,1 上下文越来越长计算量爆炸,2 检索器和生成器独立训练导致优化目标不一致,3 梯度断流的问题 在NQ、HotpotQA、MuSiQue、2Wiki上,不同压缩比4×/16×/32×均保持领先,压缩到32×时仍优于未压缩的纯检索基线 上下文长度最高可压32×–64×,同时保留了生成准确答案所需的基本信息 具体是,1、首先压缩预训练,把文档压成32~256维向量,保留QA/复述语义 2、然后指令微调,让压缩向量适配下游问答任务 3、再端到端联合训练,检索器+生成器一起优化 #RAG #mlclara