
Tweet Overview
View this X/Twitter post from @sitinme published on 25 Aralık 2025 02:13. This post contains 8 images.
SEO 到底怎么系统学? 一个很重要的共识是:SEO 不是靠速成课,而是靠长期高质量英文信息源的“肌肉记忆”。Pollo AI 创始人阿彪在播客里提过,他的 SEO 能力就是靠多年刷英文博客练出来的——排队、吃饭、通勤,全是学习时间。 一句话总结:日拱一卒,长期复利。 如果只推荐一个入口,我那就Ahrefs Blog。 哪怕你完全不用 Ahrefs 的工具,他们的文章也几乎是SEO 实战范本:关键词拆解、内容结构、外链策略、失败案例复盘,全部是可复制的方法论。建议新手先把它当教材从头刷一遍,会迅速建立正确的 SEO 世界观。 在此基础上,可以补两类内容: 第一类是系统方法论,比如 Backlinko、Authority Hacker。它们特别适合想做“工具站 / 利基站(Niche Site)的人”——核心逻辑就是: 找一个足够具体的问题 → 用内容或工具做到“最垂直、最深” → 大站看不上,你反而有机会排到第一页。 Authority Hacker 提出的 4C 模型(Create / Connect / Capture / Convert),本质就是一套从搜索流量到变现的完整闭环,非常适合技术背景的人理解和落地。
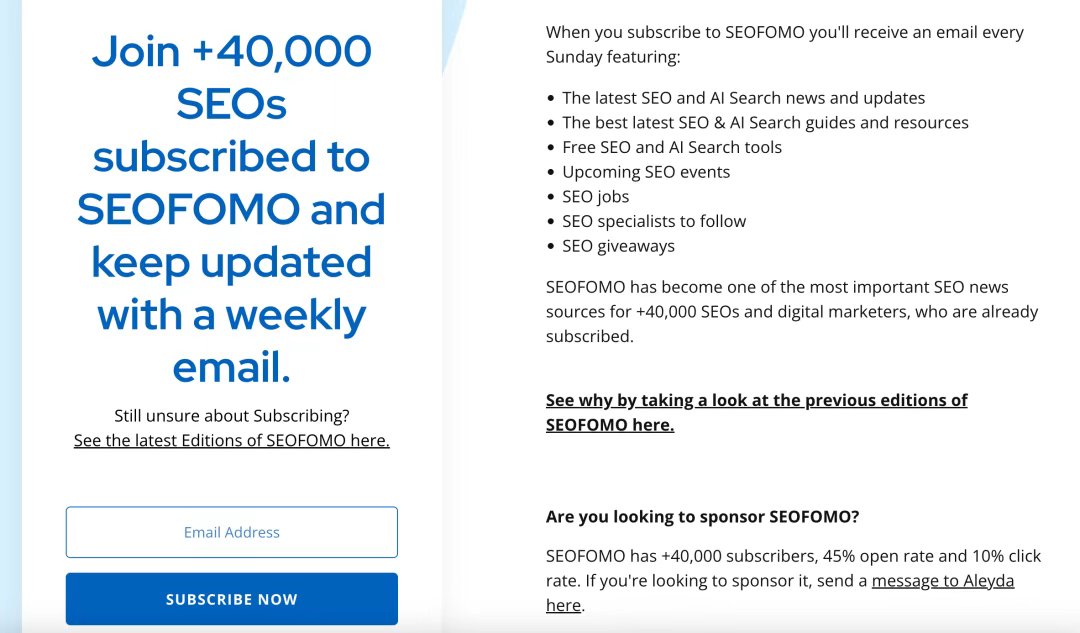
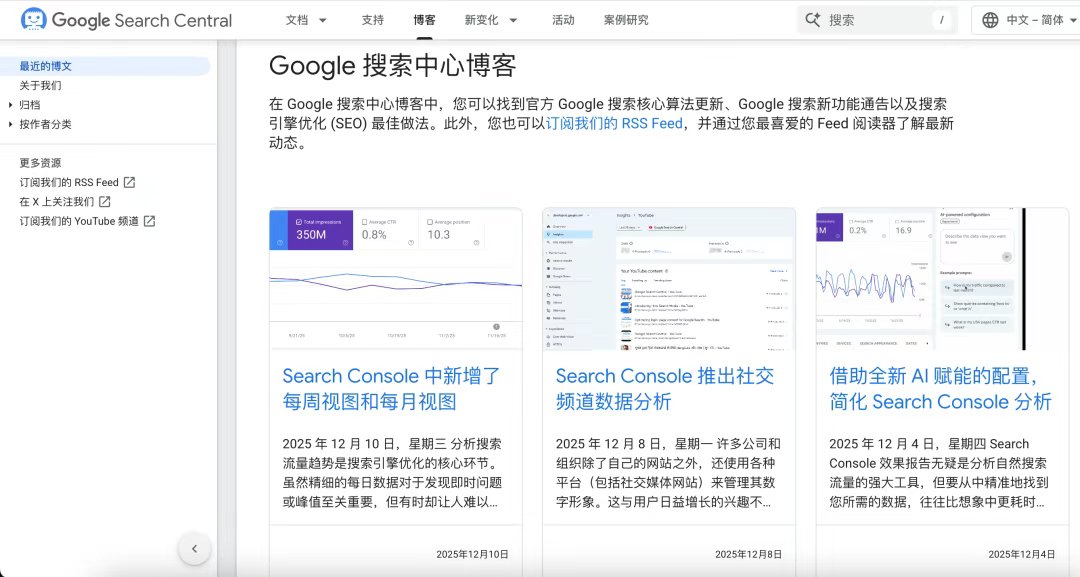
第二类是高频信息源,用来“感知风向”。 比如 SERoundtable、Search Engine Land、Google Search 官方博客,这些不用精读,刷标题 + 摘要就够了,主要目的是: ·感知算法波动 ·理解 Google 在关注什么 ·避免走明显的坑 再往上走一步,就是订阅制学习。 像 SEOFOMO、Kevin Indig 的 Newsletter,本质是帮你做了“信息筛选”,更偏战略、增长、产品视角,对程序员、独立开发者非常友好。 最后: 把这些全部系统化、自动化。 用 RSS 把所有博客聚合,用 Read-it-later 存长文,用 X 关注少量高质量账号。减少“找信息”的成本,把精力留给理解和执行。 说到底,SEO 真正拉开差距的不是“看了多少”,而是: 看到一个方法 → 立刻在自己的网站上试一次。 哪怕失败,积累的也是自己的数据。 长期来看,这才是 SEO 修炼真正的复利来源。

简单介绍下自己,方便大家交流 1. Python程序员,在成都,创业4年 2. 主要做知识付费,爬虫,RPA自动化机器人,AI工具等等。 如果你喜欢我的分享,欢迎添加vx:257735或扫码 ,备注来自 「twitter」回复【出海资料】即可免费领取《AI 编程出海蓝皮书》






